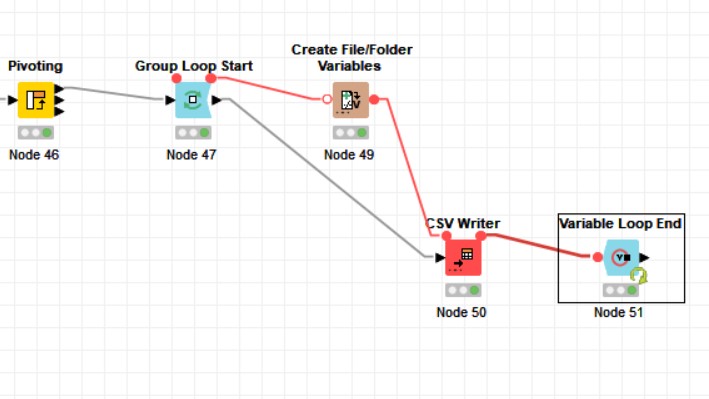
Durante il nostro corso Knime Core Concepts, Federica ci ha fornito alcuni ottimi casi d’uso in cui possiamo sfruttare un software di modellazione dei dati come Knime utilizzando i nodi. Una di queste grandi caratteristiche, che mi ha davvero sorpreso, è la possibilità di creare più output desiderati in “.csv” utilizzando i nodi “Loop” e “Variable”. Vediamo insieme come facciamo la creazione di più file CSV utilizzando “Loop” in Knime
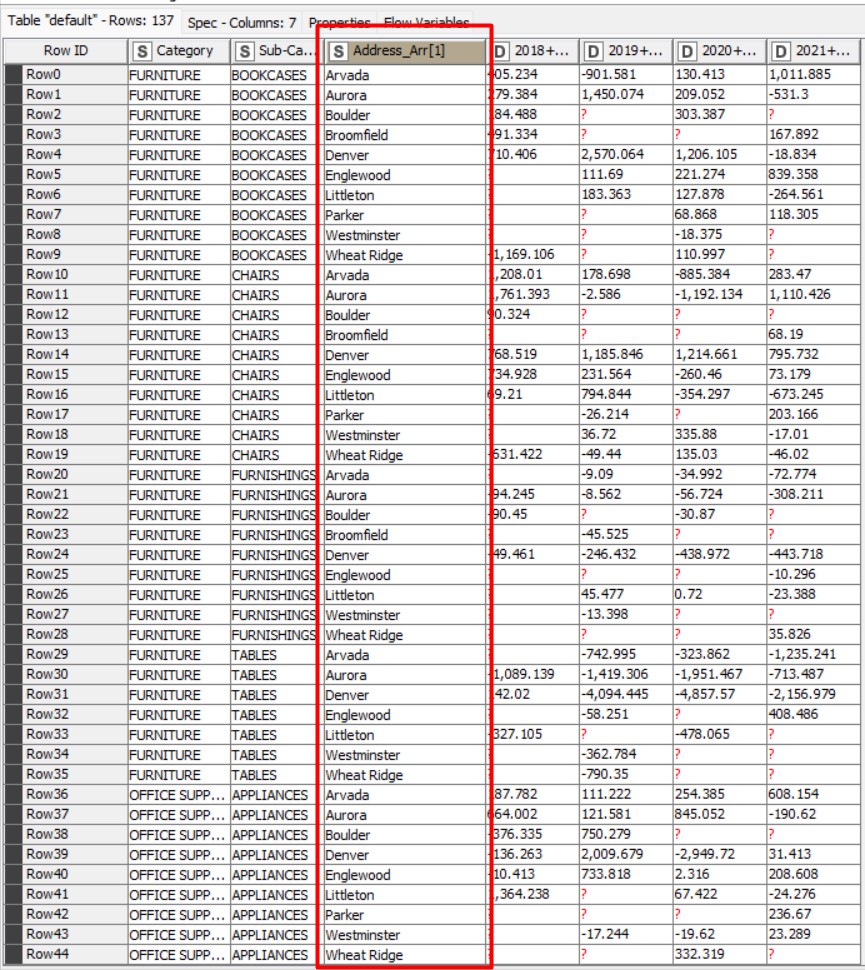
Ho un output desiderato di tutti i processi di manipolazione dei dati alla fine del mio flusso di lavoro e ora voglio creare alcuni file “csv” basati sul gruppo di città in una delle mie colonne denominate “Address_Arr[1]”, come puoi vedere nell’immagine. Ad esempio, voglio un file csv per “Arvada”, un altro per “Aurora” e così via.
Se porto semplicemente un nodo “CSV Writer” al mio flusso di lavoro e lo eseguo, non mi darà i file di cui avevo bisogno. La risposta a tale dilemma è usare i loop. Dobbiamo creare un ciclo per estrarre i valori desiderati e creare i file “csv” uno per uno. Colleghiamo un “Group Loop Start” al nostro output e apriamo la configurazione del nodo.
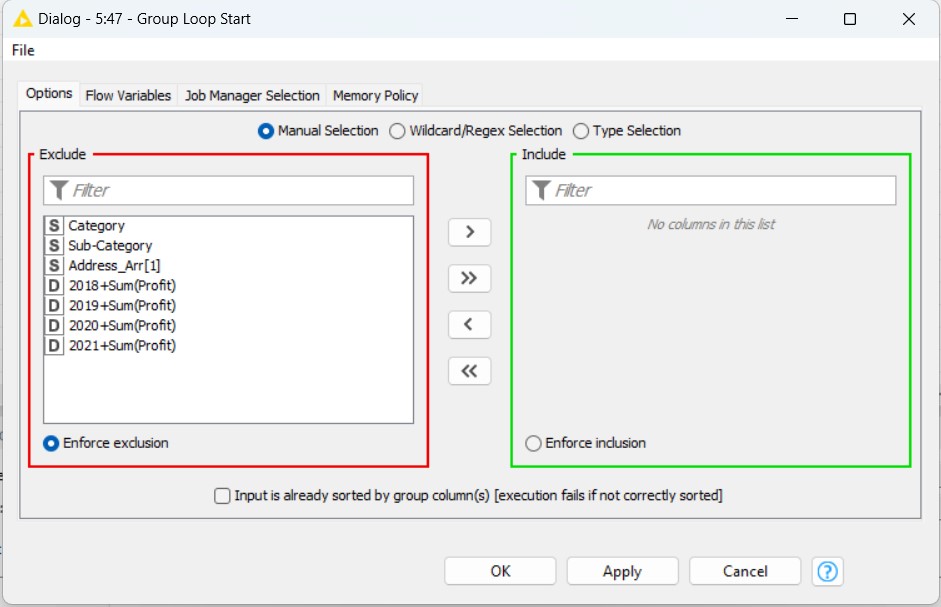
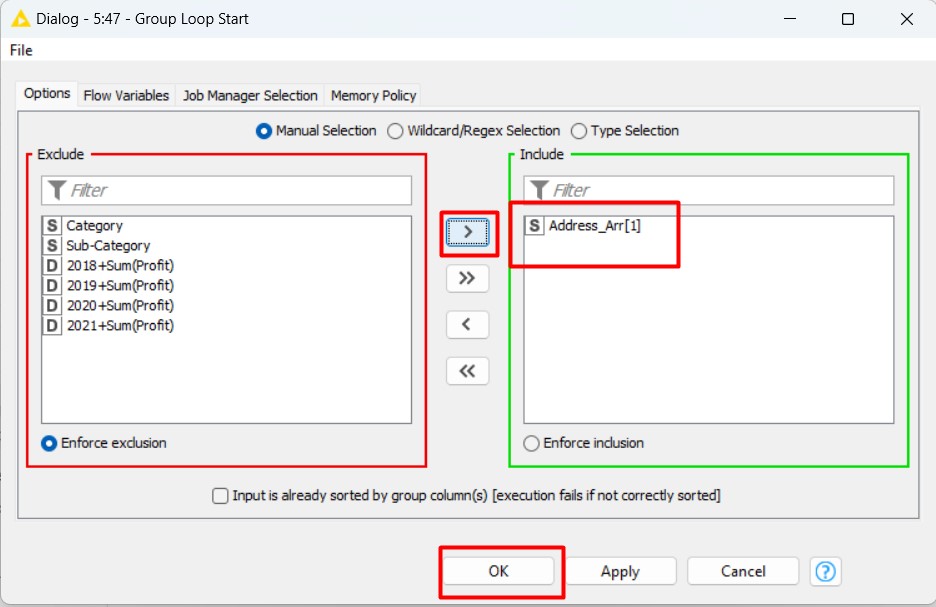
Nella finestra di dialogo di configurazione, possiamo vedere due set (Exclude, Include). Dobbiamo portare la colonna o le colonne di nostra preferenza nella parte di inclusione, in questo caso “Address_Arr[1]”. Non abbiamo bisogno di cambiare nient’altro e, facendo clic su OK ed eseguendo il nodo e siamo un passo più vicini al nostro risultato preferito.
La parte più importante è il passo successivo. In questo passaggio, vogliamo definire alcune variabili in base ai nostri gruppi desiderati, in questo caso le città. Il nodo che serve il nostro bisogno qui è “Create File/Folder Variables”. Quello che fa è completare il puzzle del percorso in cui vogliamo i file csv.
Come suggeriscono il nome e la forma di questo nodo, funziona con le variabili. Pertanto, se vogliamo collegarlo al nostro flusso di lavoro, dobbiamo attivare le porte variabili del “Group Loop Start” facendo clic destro su di esso e mostrare le porte variabili del flusso.
Due porte vengono visualizzate sul nodo “Group Loop Start”. Quella di sinistra è la porta di ingresso e quella di destra è la porta di uscita di cui abbiamo bisogno.
Dobbiamo collegare la porta di output di esso alla porta di ingresso del nodo Create File/Folder Variable”.
Apriamo la configurazione del nodo “Create File/Folder Variable” e vediamo cosa dobbiamo fare.
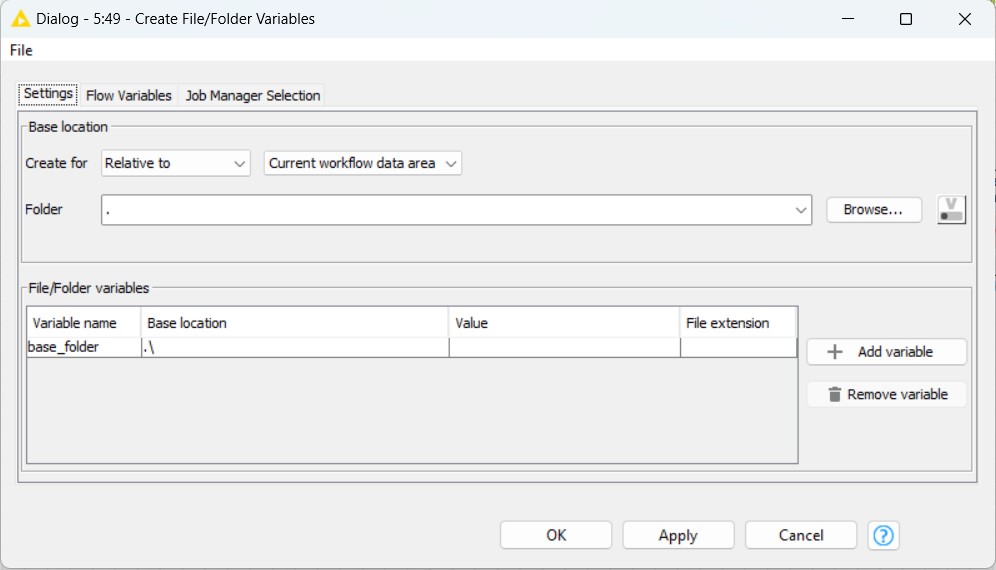
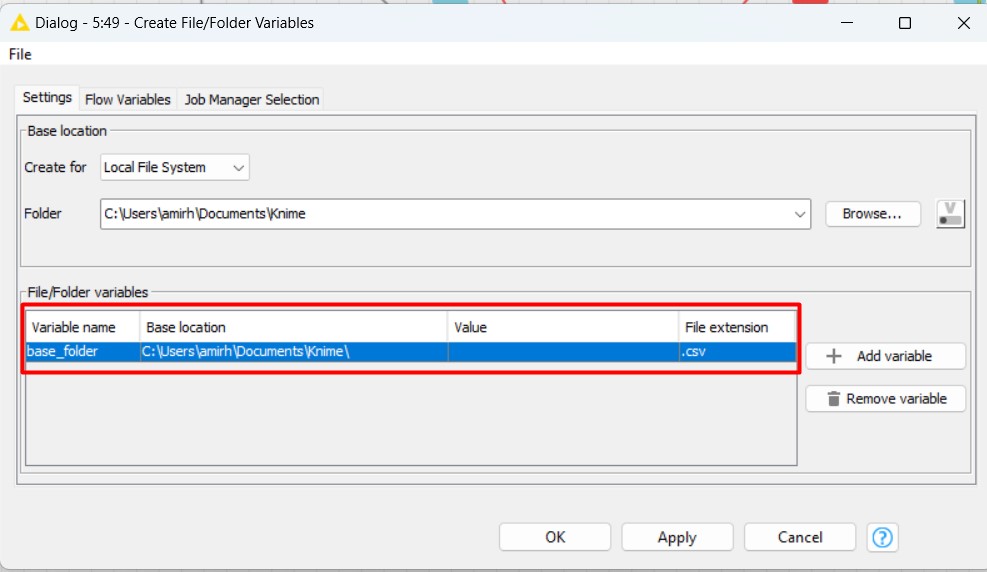
Nella parte “Base location”, dobbiamo scegliere una cartella in cui vogliamo salvare i nostri file. Pertanto, scegliendo il “Local File System” e quindi facendo clic su “Browse…” l’impostazione dovrebbe essere impostata come l’immagine seguente.

Quindi nella parte “File/Folder variables”, possiamo vedere quattro colonne che creano il percorso per noi.
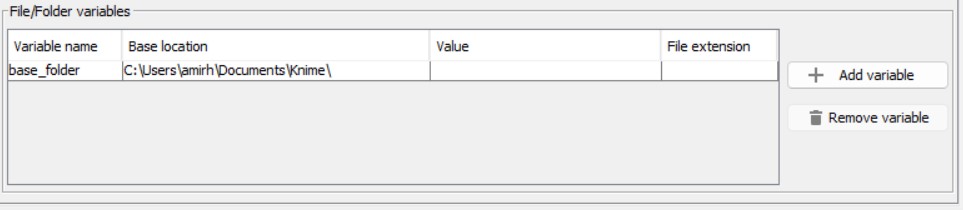
La “Base location” del percorso è quella che abbiamo appena impostato. Il “Value” è il nome dei gruppi che vogliamo avere sui nostri nomi di file, che imposteremo in un minuto. Infine, il “File extension” è “.csv”. Facendo doppio clic su “File extension”, possiamo digitare “.csv” per questa parte.
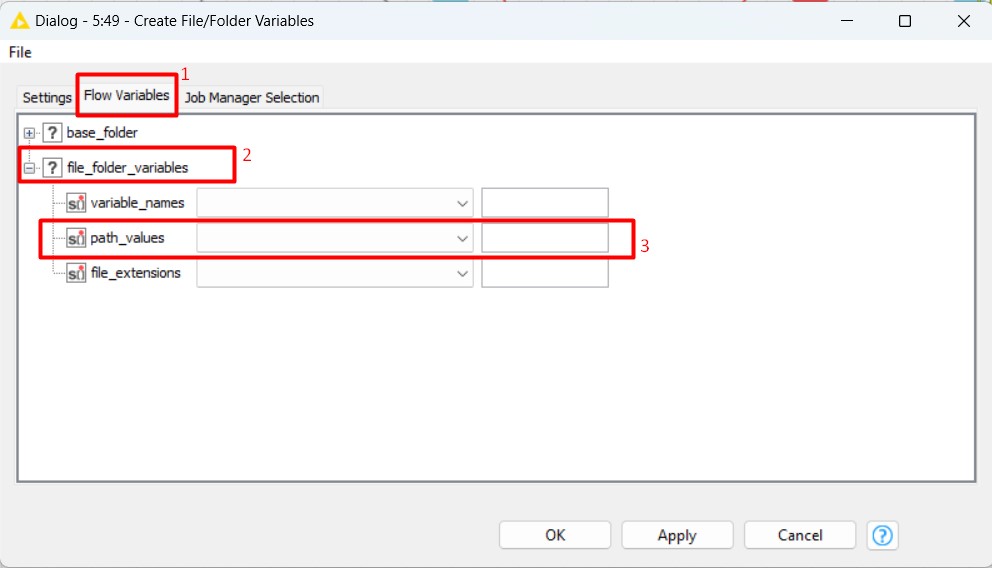
Ora, andiamo alla scheda “Flow Variables” nella stessa pagina di dialogo e troviamo il “path_values” nelle opzioni.
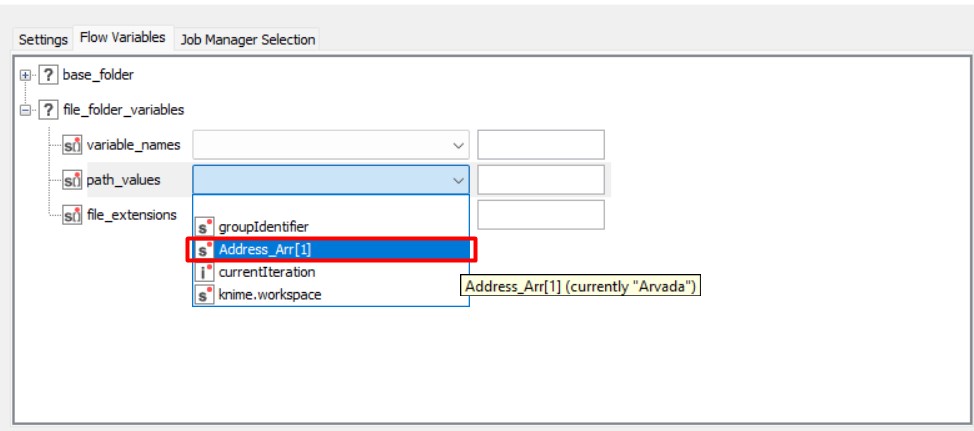
“path_values” sono i nomi dei file che stiamo cercando (il nome delle città nella nostra colonna indirizzo). Cliccando sulla piccola freccia, apparirà il nome delle colonne della nostra tabella, e dobbiamo scegliere quello che contiene i nomi richiesti, in questo caso “Address_Arr[1]”.
Ora che abbiamo completato la nostra attività in questo nodo, possiamo fare clic su OK ed eseguire il nodo. Se facciamo clic con il pulsante destro del mouse su questo nodo e apriamo ” Flow Variables with path information”, possiamo vedere il percorso creato per il primo file.
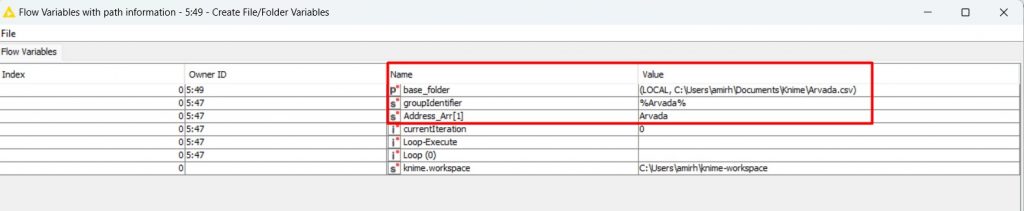
Dobbiamo inserire queste variabili nel ciclo nel nodo “CSV Writer”. Quindi, portiamo questo nodo al nostro flusso. E ancora una volta accendi le sue porte variabili come nell’immagine seguente e collega la porta di output di “Create File/Folder Variables” alla porta di ingresso del “CSV Writer”. Dobbiamo anche collegare il “Group Loop Start” al “CSV Writer”, quindi apriamo la sua impostazione di configurazione.
Nella pagina di dialogo aperta, possiamo impostare il percorso sul nostro sistema locale nella prima parte.
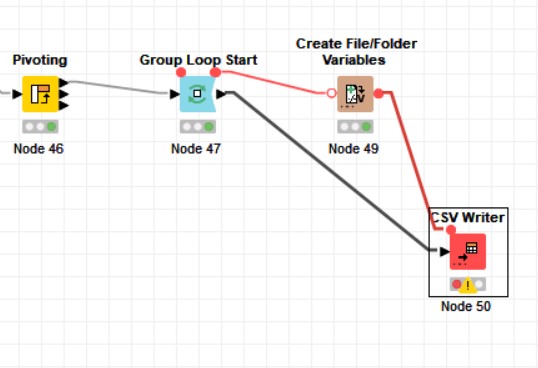
Ma finora abbiamo creato i percorsi e ciò di cui abbiamo bisogno è fare clic sul pulsante “V” accanto a “Browse…” bottone.
Cliccandoci sopra, possiamo vedere la seguente immagine.
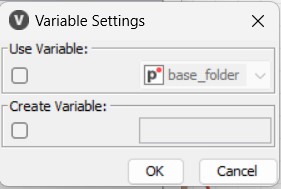
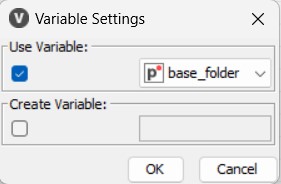
Se spuntiamo l’opzione “Use Variable”, possiamo avere la variabile (base_folder) che abbiamo creato nel nodo precedente che è in realtà di tipo “Path”.
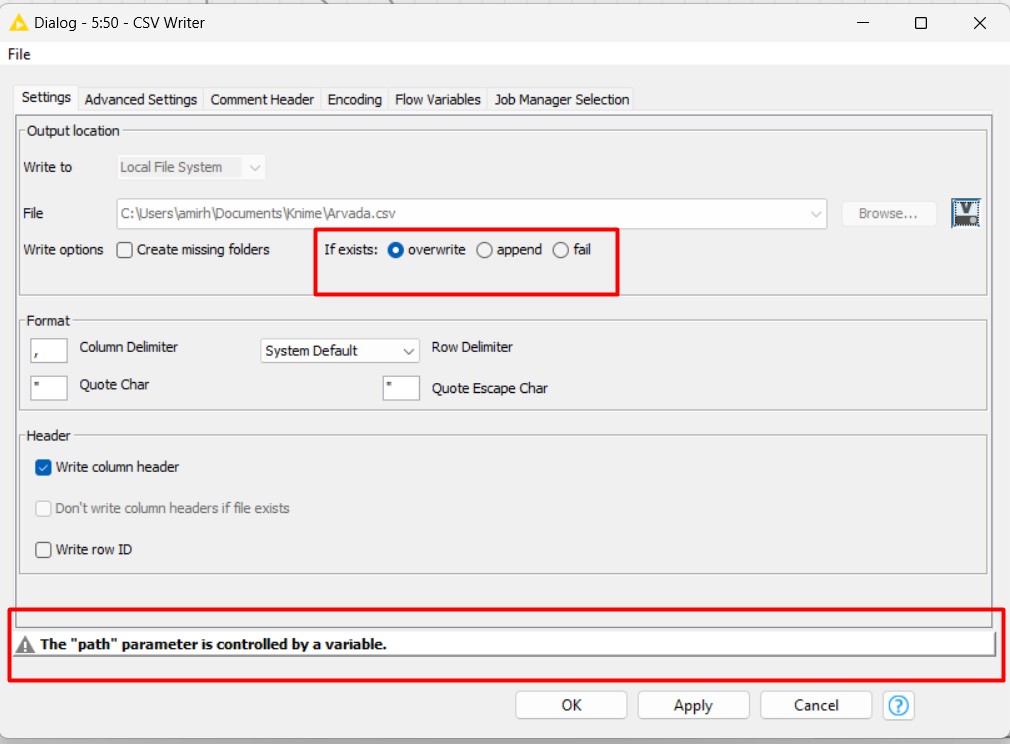
Alla fine, possiamo vedere la nota sotto la pagina di dialogo che dice che il parametro “path” è controllato da una variabile. Dobbiamo anche chiarirlo per Knime nei casi in cui trova lo stesso file nella cartella desiderata. In altre parole, diciamo a Knime cosa fare in questi casi. Poiché potremmo aggiornare il nostro flusso di lavoro o aggiornare i dati, è meglio dire al nodo Writer di sovrascrivere sui file precedenti.
Ora abbiamo creato il primo file desiderato. L’ultima cosa che dobbiamo fare è chiudere il nostro ciclo per avere tutti i file nel percorso impostato. Per fare ciò, portiamo la “Variable Loop End” al flusso di lavoro e colleghiamo la porta della variabile di output del nodo writer alla sua porta ed eseguiamola (non c’è nulla da impostare in questo nodo per il nostro caso d’uso).
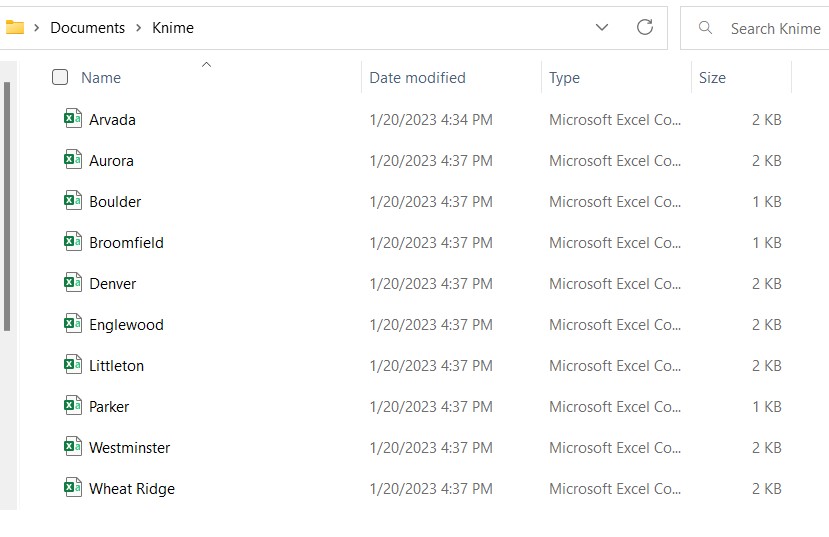
Ora, se andiamo alla cartella, vediamo tutti i file csv creati da questo flusso. Incredibile, vero?
Spero che tu possa utilizzare questa funzione nei tuoi casi d’uso e flussi di lavoro per creazione di più file CSV utilizzando “Loop” in Knime