Questo nodo sfrutta un carattere di delimitazione specificato dall’utente per suddividere il contenuto di una colonna selezionata in più parti. È possibile specificare se l’output è costituito da una o più colonne, da una sola colonna contenente una lista o da una sola colonna contenente un set (in cui vengono rimossi i duplicati a differenza della lista).
Esempi di caratteri di delimitazione: . ; / “ “ etc…
Come usare il cell splitter:
- Situazione iniziale: Una tabella contenente una colonna che rappresenta nome e cognome

- Aprire il pannello di configurazione del Cell Splitter e selezionare la colonna che si vuole suddividere (employee_name) :

- Definire il carattere di delimitazione che ci permetterà di suddividere la colonna (Uno spazio vuoto in questo caso) :

Di default l’impostazione “Remove leading and trailing white space chars“ rimane attivata, tale proprietà permette di eliminare eventuali spazi vuoti che potrebbero essere presenti prima o dopo i caratteri delle colonne di output.
Di fianco alla colonna selezionata è possibile attivare la funzione che elimina la colonna di origine dopo averla suddivisa. Per mostrare al meglio le varie operazioni, in questo caso rimarrà disattivata.
- Sezione di personalizzazione dell’output:

Come descritto nell’introduzione, è possibile definire 3 tipi di output:
- Una lista
- Un set
- Nuove colonne
L’impostazione di default è come quella della schermata superiore: definendo nuove colonne come tipo di output e usando l’impostazione “Guess size and column types” che permetterà al software di indovinare il numero di colonne richieste per l’output.
- È comunque possibile definire manualmente la quantità di colonne che desideriamo in output usando “Set array size”:

In questo caso sarà compito dell’utente capire quanti elementi è possibile estrarre dalla colonna iniziale, a meno di esigenze specifiche è consigliabile usare l’impostazione automatica “Guess size and column types”.
- Eseguire il nodo Cell Splitter

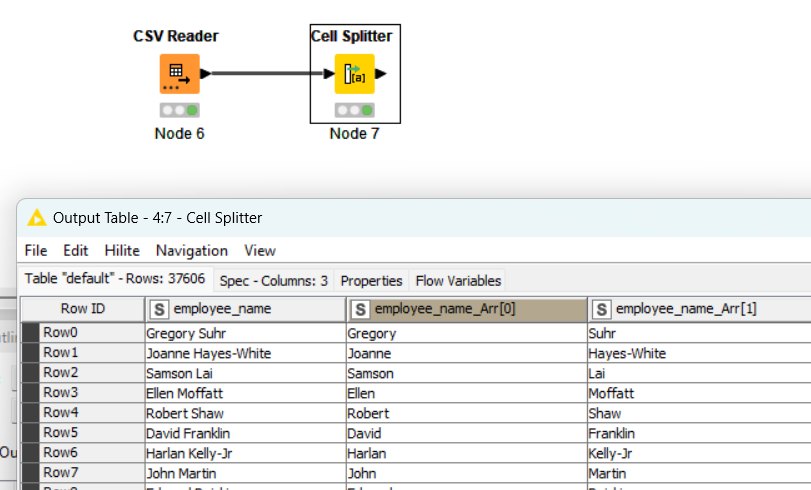
- Questo è il risultato finale:
Possiamo osservare che sono presenti due nuove colonne derivanti dalla nostra colonna iniziale : “employee_name_Arr[0]”, “employee_name_Arr[1]”
Il nome è stato correttamente suddiviso in due colonne, separandole sulla base del carattere di separazione deciso inizialmente.
Ogni nuova colonna generata, sarà rinominata come:
il nome della colonna inziale + _Arr[x]
Dove x definisce il numero della sezione.
Conclusione:
Il nodo Cell Splitter risulta indicato ogni qualvolta si riscontri la necessità di suddividere il contenuto di una colonna sulla base di un carattere di delimitazione.
La sua funzionalità di definizione automatica del numero di colonne di output risulta efficace e permette di velocizzarne l’utilizzo.