Nel caso in cui si vogliano fare delle aggregazioni in Knime possiamo utilizzare il nodo GroupBy.
Questo nodo crea una riga per ogni valore delle colonne selezionate come raggruppamento. L’output conterrà quindi una riga per ogni combinazione di valori unici per le colonne selezionate.
Andiamo a vederlo più in dettaglio.
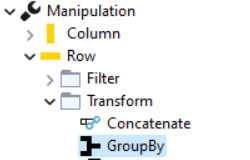
Per prima cosa, il nodo GroupBy si trova nel node repository sotto Manipulation -> Row -> Transform -> GroupBy
Una volta trascinato il nodo la tab che possiamo aprire si presenta in questo modo:
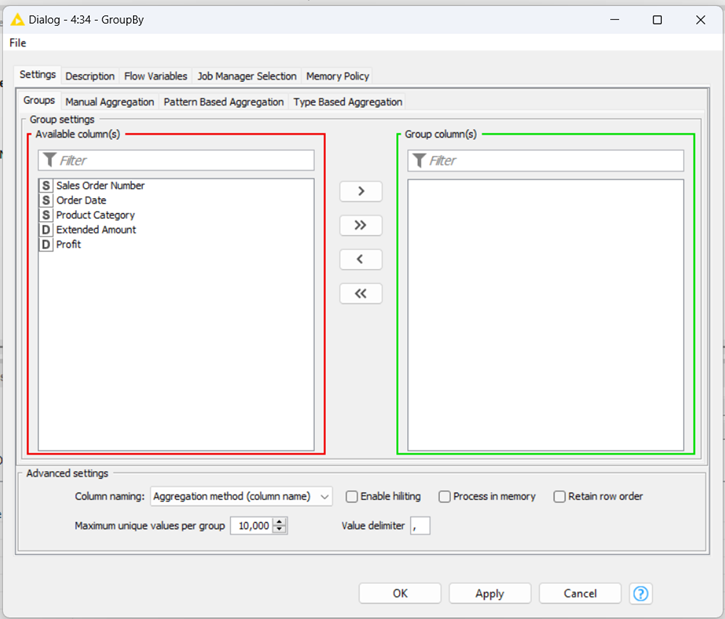
Sotto Settings e Groups, ovvero dove ci troviamo appena apriamo il GroupBy, dobbiamo andare a selezionare quali colonne vogliamo utilizzare per raggruppare i nostri dati, andandoli a inserire nella Group column(s).

Semplicemente selezionando le colonne di interesse e cliccando sulla freccia verso destra queste colonne diventeranno le nostre selezioni.
Tipi di Aggregazioni
A questo punto, sempre sotto Settings, ci spostiamo a decidere il tipo di aggregazione che vogliamo fare.
Per questo abbiamo tre opzioni.
La prima è Manual Aggregation, che permette di selezionare manualmente le colonne da aggregare.

In questo caso ho deciso di aggiungerle tutte e tre.
Quindi, possiamo cambiare il tipo di aggregazione accanto al nome della colonna.
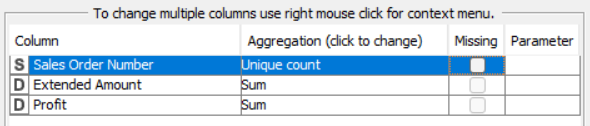
Ho deciso di aggregare una colonna per unique count e le altre due per sum.
La seconda opzione è quella di utilizzare una Pattern Based Aggregation.
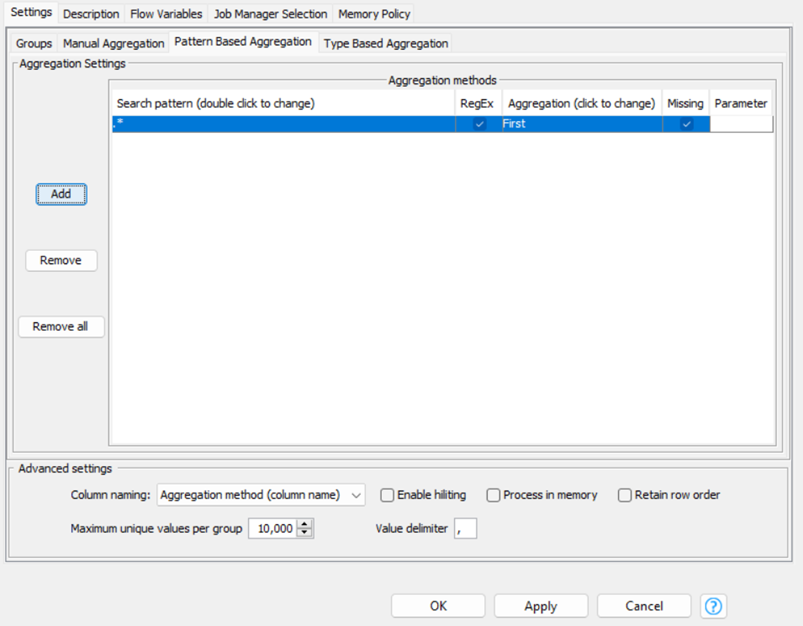
Cliccando su Add possiamo aggiungere le colonne da aggregare. Questo è wildcard, utile quindi nel momento in cui alcune colonne con una parte del nome comune potrebbero essere aggiunte, rendendo in questo modo il nostro flusso di lavoro più dinamico.

Nel mio caso ho inserito Amount preceduto da *. Questo significa che se venissero aggiunte successivamente delle colonne con Amount alla fine e qualcos’altro davanti, anche queste saranno aggregate come Unique count.
Infine, è presente la Type Based Aggregation. Come dice il nome, questa opzione consente di aggregare le colonne basandoci sul loro data type. È simile al wildcard, con la differenza che non andiamo a scegliere le colonne in base al nome ma in base alla loro tipologia.
Può inoltre essere utile perché, nel caso in cui non abbia un determinato data type tra i miei dati ma so che potrebbe essere aggiunto in seguito, questo viene automaticamente aggregato da selezione, rendendo anche in questo caso il flusso di lavoro molto più dinamico.
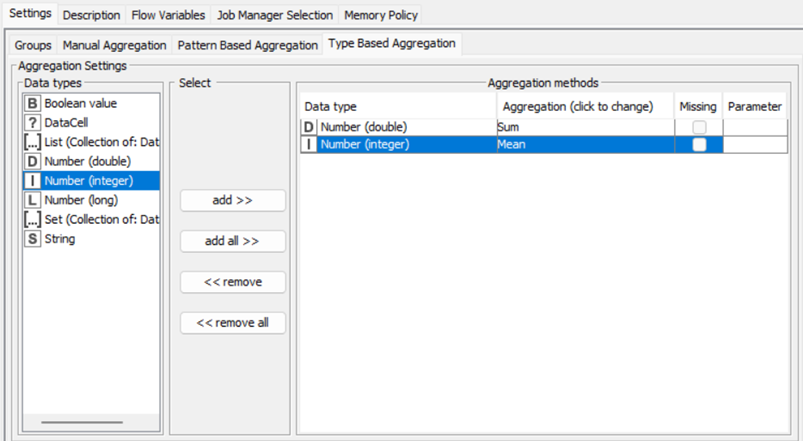
Nelle advanced settings in basso alla tab, abbiamo l’opzione su come vogliamo rinominare le nostre nuove colonne. Qui possiamo decidere se tenere il nome originale, se chiamarle con il metodo di aggregazione e, tra parentesi, il nome della colonna o il contrario, ovvero il nome della colonna e, tra parentesi, il metodo di aggregazione.

Missing Box
Ogni volta che andiamo a selezionare un tipo di aggregazione possiamo notare dei box in una colonna denominata Missing.

Questo significa che, nel caso in cui siano presenti dei valori nulli posso decidere se andarli ad escludere o meno. Questo perché questi valori nulli potrebbero essere aggiunti come 0. Nel caso di una somma, ad esempio, non c’è alcun problema, ma nel caso di una media questo potrebbe risultare in un diverso risultato, in quanto sarebbero conteggiati nel divisore. Fate quindi attenzione su quando spuntare o meno questo box!
Tra Knime e Tableau
Piccola curiosità: se decidiamo di fare un GroupBy non andando ad inserire niente tra le colonne da raggruppare, ma se decidiamo di mettere ad esempio l’anno aggregato per il massimo, quello che otteniamo è il corrispondente di una FIXED LOD Max di anno in tableau!